Federated Learning e Bioinformática: Pesquisa no mundo dos dados sensíveis e diplomacia dos dados - Parte 1 : Introdução ao Federated Learning
Explore os conceitos de Federated Learning aplicados à Bioinformática, abordando a importância da privacidade dos dados e o impacto na diplomacia dos dados.
Created Mar 18, 2024 - Last updated: Mar 18, 2024

Federated Learning e Bioinformática: Pesquisa no mundo dos dados sensíveis e diplomacia dos dados - Parte 1: Introdução ao Federated Learning
Por Pedro Medeiros e João Vitor F. Cavalcante
Durante o Evento Insights Lab, promovido pelo Instituto Roche e com a presença de pesquisadores brasileiros apoiados pelo Instituto Serrapilheira, a experimentação com a tecnologia de Federated Learning/Analysis foi um destaque. Este texto, dividido em duas partes, explora seu conceito, possibilidades e possíveis usos para a bioinformática — especialmente no âmbito biomédico — e o impacto que isso tem sobre a diplomacia dos dados.
Definição e princípios básicos do Federated Learning
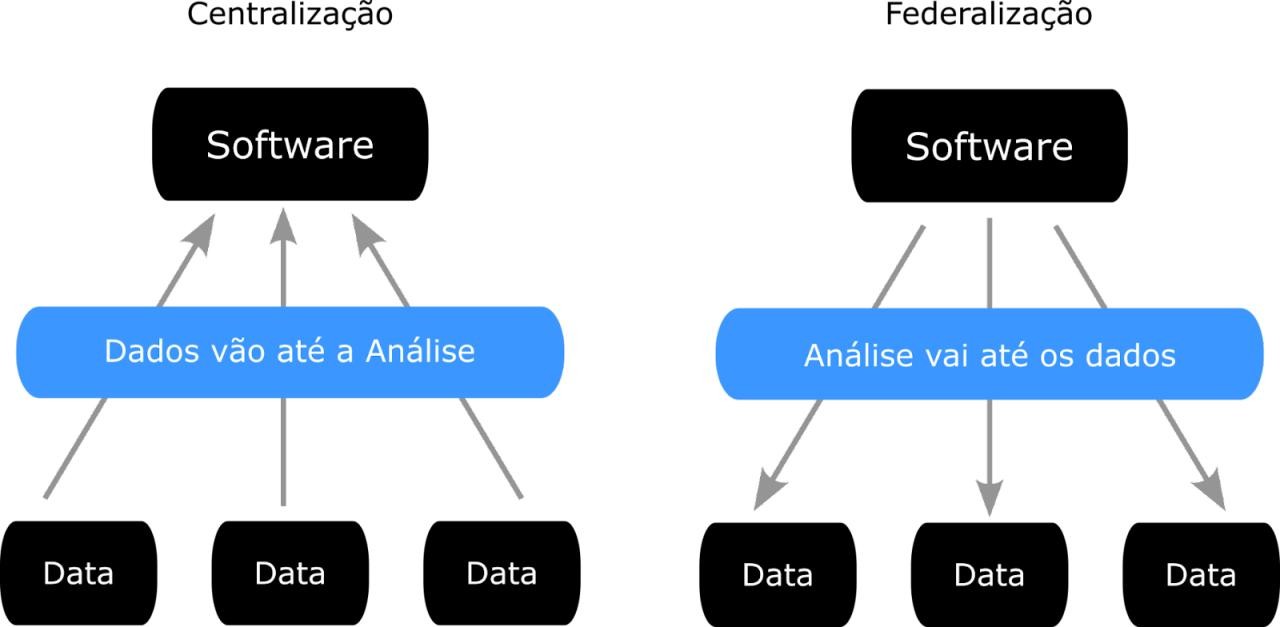
O conceito de Aprendizagem Federada (Federated Learning) surgiu como uma solução para os desafios relacionados à privacidade dos dados, eficiência da comunicação e descentralização no treinamento de modelos de aprendizado de máquina. A ideia foi introduzida e popularizada pela Google em 2017, com o objetivo de treinar modelos de aprendizado de máquina diretamente nos dispositivos dos usuários, como smartphones, sem a necessidade de enviar seus dados pessoais para servidores centrais.
Entre os motivadores para seu desenvolvimento estava a descentralização da geração de dados em dispositivos móveis, no entanto, regulações de proteção dos dados de usuários como o Regulamento Geral de Proteção de Dados (GDPR) europeu influenciaram fortemente o aspecto de privacidade e acesso hierárquico possibilitados pela tecnologia.
Portanto, a Aprendizagem Federada pode ser descrita como um modelo de aprendizagem de máquina que permite treinar um algoritmo de inteligência artificial (IA) em múltiplos dispositivos ou servidores descentralizados sem a necessidade de centralizar os dados em um único local. As operações são enviadas aos clientes, ou instituições federadas, que realizam o processamento no seu dado local, e o que é retornado é apenas os pesos do modelo, garantindo privacidade completa. Este modelo é especialmente útil para situações em que os dados são sensíveis, pessoais ou confidenciais, e não podem ser compartilhados ou transferidos devido a preocupações com privacidade, segurança ou regulamentações de dados.
Visão geral da bioinformática e sua relevância para a pesquisa biomédica moderna
Para quem trabalha com bioinformática, não é novidade a manipulação de grandes volumes de dados, a variabilidade biológica e a necessidade de grandes grupos estatísticos para pesquisa sempre foi uma pressão sobre a área. Para lidar com esses desafios, as soluções encontradas até agora eram o uso de grandes bancos abertos (valendo-se de uma estratégia Open Data), como o EMBL e o NCBI, uso de supercomputadores ou clusters oriundos de consórcios acadêmicos e uma forte pressão sobre a eficiência dos algoritmos de análise. Todos esses recursos e táticas, como pode ser notado, implicam em centralização dos dados e das análises, o que implica em certas limitações e aumento do trabalho em estudos cuja geração das informações não necessariamente são centralizadas.
Neste contexto de grandes volumes e centralização, a pesquisa biomédica apresenta desafios especiais. A necessidade crítica de manter a privacidade, a confidencialidade e a segurança dos dados ao lidar com informações que são frequentemente pessoais e potencialmente identificáveis prejudicam o uso da estratégia de Open Data para esse tipo de pesquisa.
O risco de que os dados genéticos e de saúde sejam usados para discriminar indivíduos em vários contextos, incluindo emprego, seguros e acesso a serviços, as dificuldades e barreiras éticas na busca da obtenção do consentimento informado em diversos contextos somados a desafios políticos, regulatórios a serem endereçados de maneira técnica acabam, por muitas vezes, impedir que a abordagem bioinformática à pesquisa biomédica realizem o seu potencial já permitido tecnologicamente.
Natureza sensível dos dados biomédicos e questões de privacidade
A proteção desses dados é fundamental não apenas para a segurança e privacidade dos indivíduos envolvidos, mas também para manter a confiança pública na ciência biomédica e na pesquisa. São várias as regulamentações e acordos que versam sobre o tema, de maneira que um texto só para isso seria necessário. Para fins de referência
, coloco abaixo alguns dos acordos e regulamentações que, direta ou indiretamente, promovem o desenvolvimento de tecnologias para acesso parcial dos dados para fins de proteção dos indivíduos e da sociedade em diversos países:
- Regulamento Geral de Proteção de Dados (GDPR)
- Lei de Portabilidade e Responsabilidade de Seguro Saúde (HIPAA)
- Declaração de Helsinque
- Diretrizes do Conselho de Organizações Internacionais de Ciências Médicas (CIOMS)
- Lei Geral de Proteção de Dados Pessoais (LGPD)
Fora esses desafios específicos da área, há um contexto mais geral que impulsiona a sociedade, governos e organizações a pensarem em acessos mais controlados aos dados. A internet nasce e se desenvolve em parte em torno de valores conectados à contracultura americana dos anos 70/80: abertura, compartilhamento, liberdade e afins. A grosso modo poderíamos resumir a história até o contexto de Open Data que até hoje é vigente e impulsiona muitas pesquisas no mundo todo (o dos autores deste texto incluso), no entanto, a evolução das disparidades nas capacidades de aproveitamento desses dados e estímulos econômicos levam a questionamentos bastante razoáveis sobre o uso e destinos dos dados que são produzidos. Dados passam a ser, agora, valiosos e, portanto, ativos a serem negociados entre corporações e governos, dando origem à chamada “Diplomacia dos dados”.
A Diplomacia dos Dados reflete um paradigma emergente nas relações internacionais, onde a posse, o acesso e o controle sobre dados transformam-se em elementos estratégicos vitais para a segurança nacional, desenvolvimento econômico e influência global. Neste contexto, os dados não são apenas ativos econômicos, mas também ferramentas de poder e negociação, moldando novas formas de cooperação, competição e conflito entre nações. Governos e organizações internacionais buscam estabelecer normas e acordos para regular o fluxo transfronteiriço de dados, equilibrando interesses de privacidade, inovação e segurança.
Além da diplomacia de dados, outro ponto enfrentado pelas atuais estratégias de gerenciamento de dados é a proveniência de dados (data provenance), ou como os dados foram originados, transformados e disponibilizados. Com grandes modelos de aprendizado e dados abertos, essa informação costuma se perder na linha de processamento, o que é bastante problemático. O aprendizado federado, por possibilitar operações nos locais de origem dos dados, também pode facilitar a descrição de sua proveniência.
Essa foi a parte 1 do texto acerca de Federated Learning e Bioinformática. Em breve postaremos a parte 2 com exemplos de projetos, considerações éticas, políticas e afins.
Até a próxima!